In a nutshell
You put in a data-warehouse all the data of your enterprise.
This data will be imported from diverse sources; and especially operational ones (e.g. the production
database of your e-commerce website).
The goal of a DWH is to offer a single data-model (that
usually sits within a relational DB), so that data-analysts can ultimately*
create reports about the data, for “business people” (i.e. the decision makers
of the company).
*Please note that data-analysts don’t directly work on the
DWH; they work on data-marts.
Data-marts are spin-offs of the DWH, but they usually only include a subset of
the data, and have their data-models optimized for the specific type of
analytics they will be submitted to.
 |
| You will periodically load into your DWH data extracted from your many operational-sources. You will then do the same for your data-marts, which are used by data-analysts. Note that the yellow lines are dotted, because I am hiding some intermediary steps |
Benefits of a DWH
·
single point of truth: information about
the same object may be contained in many different operational sources, with
different attributes for the same business-object (e.g. SURNAME=”Leo” and
SURNM=”Leo”), and even sometimes with conflicting values (e.g. 2 sources giving
different addresses for the same person). To perform our analysis, we need a
single point of truth: the DWH. Hence, before importing data into the DWH, the
data will have to be cleaned (e.g. make sure it has the same format and that
the format is correct, resolve conflicting values, etc.), and merged (when you
have diverse sources containing pieces of information about the same business-object)
before being imported into the DWH.
·
Data historization: in a DWH, you keep a
history of the values of your data. Hence, if the value of a meaningful (business-wise)
attribute is updated, you will also keep its former value.
For instance, if a customer updates his address on your website, the operation
DB (OLTP) powering the website will simply perform an UPDATE statement. But
during the next import batch to the DWH, you will add/log the new value, while
keeping the former.
This means that the data-model of a DWH will necessarily be different from the
one in the operational source (as the DWH’s data-model need to be able to log
historical values).
·
The data model is designed to provide
business-facts to business people, instead of plain data. You will optimize
query performance (e.g. use an adequate data model, build the proper indexes, query profiles, set up database
parameters) specifically for the purpose of reporting/analytics (while
operational systems are optimized for transactional task).
·
You will perform your analytics by reading the
data-marts (which receive their data from the DWH), instead of performing your
analytics against the operational systems. Hence, your analytics will not
induce any performance impact on operational-systems.
Note: sure, performing the extract batches
on operational-systems (extracting the data that will ultimately be loaded into
the DWH) does reduce the performance of the transactional tasks that are performed
at the same time. But you can perform your extracts
at night, or against a standby data-source (e.g. a standby DB, set up with Active Data Guard).
ETL
You will import the data by performing regular batches, during
which you will:
- · extract the data from the different sources (and dump it into a staging area),
- transform it so that it fits into the data-model of you DWH,
- load it into your DWH.
 |
| You will extract by batches the data from the operational sources, load it into a staging area, and then transform it. Then you will perform the TEL operations again, to move from the staging area to the DWH. |
 |
| Most of the times, the staging area (called data lake) will rely on an Object Storage cloud service (because it’s cheap, and its low read&write speed is not a problem for such a purpose), instead of a relational DB. |
ETL vs ELT
ETL
Very often, those operations are done in the following
order: Extract, Transform, Load. The extract
batches are dumped into a staging-area (which may be implemented thanks to
a Hadoop cluster, an object-storage solution, an Informatica PowerCenter, an
Oracle DB, etc). As this dumping is very straight forward, we talk about ETL
instead of ELTL: i.e. we don’t mention the fact that it required loading the
data into the staging area. But the data is indeed loaded two times:
1. after
the extract, it is loaded/dumped into
the staging area
2. after
the transform, it is loaded into the
DWH.
So it would actually be more accurate to talk about ELTL instead of ETL.
ELT
You can locate the staging-area in the same machine as the
DWH. Hence the 2nd extract&load (from the staging area to the DWH)
will be very fast, as it takes place on the same machine.
When using an Oracle DB as the DWH, you can use PDBs or
schemas for the
staging area; and transform
the data in the staging-area PDBs/schemas before loading it to the DWH PDB/schema. Such approach will allow to
share the memory between the staging-area and the DWH (as they are both part of
the same Oracle instance), and hence limit network and disk usage for the
communication of both parties. This will dramatically increase the speed of the
2nd extract&load. So instead of calling it ELTL, we
call it ELT (this time, it’s the 2nd load that is not mentioned).
 |
| Description of the ELT process (Oracle Data Integration's approach). The staging area, DWH, and data-marts could all be in the same Oracle instance, but in different DB schemas. |
DWH vs Data-Marts
Data Analysts don’t perform their analytics directly on the
DWH. They use data-marts. Here’s why:
·
First of all, the DWH is usually too big to
perform your analytics directly on it. It is hard enough to establish a single
point of truth, and historize data for your whole company! Hence, data-analysts
will usually perform their analysis against data-marts; i.e. subsets of the
DWH, which only contain data that is relevant to the department they analyse
(e.g. Sales department, HR department).
·
But most of all, in order to perform analytics,
the data-model has to be optimized for analytics: you need to use a dimensional modelling (see paragraph
about Data Model).
o
The DWH is just too big to be modelled according
to a dimensional modelling. The high-degree
of de-normalisation of such a modelling would get the DWH out of hand.
o
But most of all, different departments of
data-analysts may perform many different types of analytics. Hence the data
model has to be adapted for each one of those analytics types. Each of those
departments thus need their own “subset of the DWH”, which will be modelled
(and partitioned) specifically for their analytics needs.
 |
| A Data-mart is more denormalized than a DWH, and it is modelled specifically for specific types of analytics. |
Data model
The data-model of a data-marts uses dimensional modelling:
1. You collaborate with business people to
determine what are the relevant business
facts (i.e. actions). For instance: sales,
employee dismissal, assembling the components of the machine we
sell, etc.
2. You
collaborate with them to understand what are the different entities that such a
fact involves. Those entities are called dimensions.
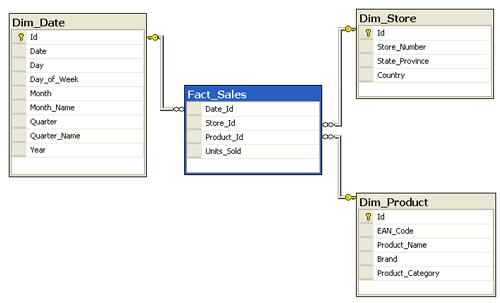
Fact Table vs Dimension Table
 |
| A star schema, with a Fact Table at the centre, and Dimension Tables all around it. |
{kind=link}


The fact table is usually the biggest one. Dimension tables are way smaller.
Star schemas and denormalization
Dimensions are usually several tables put together. For
instance, the Store dimension would include
information from several tables relating to the stores. Doing so requires to
denormalize the data-model, meaning that the same data may be repeated several
times in the dimension table, and some cells (in the dimension table) will be
set to NULL.
This denormalization is the trade-off to accept if you want to
have dimensions that include all their pertaining data; thus cutting the need
to perform many JOIN operations (which are costly).
Indeed, analytics operations usually analyse a big set of
parameters (in other words, it implies massive read operations that are especially broad-reaching). If the data pertaining
to a dimension were not assembled together (and thus not denormalized) into a
single dimension table, those analytics operations would require many JOINs,
which would mean waiting for lots of disk accesses to be performed, before being
able to gather a single result (in the resultset). But most of all, it would
mean combining the results of the different elements to be joined in a space
that is too big for memory, and would thus have to be performed on disk (with
pagination).
In an OLTP DB, you would instead normalize the data, because
you’d only need to read/write on few specific cells (the ones pertaining to the
transaction).
Tuning your data-mart
Bitmap indexes
In order to improve query performance, the DWH-architect
will generate DB indexes. With the dimensional data-model, the type of index
chosen typically is bitmap indexes.
You generate a bitmap index for each dimension of the
star-schema.



However, when using an Exadata for your DWH, a bit map index
is made obsolete: indeed, you should instead rely on Exadata’s storage indexes
(which are automatically generated; so sit back, relax, and enjoy!).
Horizontal partitioning (also used for DWH)
Partitioning will dramatically increase the speed of the
analytics queries that only require to access a few partitions (instead of the
whole table).

 |
| Note that hash-partitioning is usually not used with DWHs or data-marts. |
You’ll only partition the fact table (partitioning a dimension would most of the times screw-up the JOINs). Usually, you will partition according to the date, as most fact tables contain a date dimension.
Comments
Post a Comment